Python 网页抓取 - 处理文本
在上一章中,我们已经了解了如何处理作为网络抓取内容的一部分而获得的视频和图像。 在本章中,我们将使用 Python 库处理文本分析,并将详细了解这一点。
简介
您可以使用名为自然语言工具包 (NLTK) 的 Python 库执行文本分析。 在深入探讨 NLTK 的概念之前,让我们了解一下文本分析和网络抓取之间的关系。
分析文本中的单词可以让我们知道哪些单词是重要的,哪些单词不常见,单词是如何分组的。 这种分析简化了网络抓取的任务。
NLTK 入门
自然语言工具包 (NLTK) 是 Python 库的集合,专门用于识别和标记自然语言(如英语)文本中的词性。
安装 NLTK
您可以使用以下命令在 Python 中安装 NLTK −
pip install nltk
如果您使用的是 Anaconda,则可以使用以下命令构建 NLTK 的 conda 包 −
conda install -c anaconda nltk
下载 NLTK 的数据
安装NLTK后,我们必须下载预设文本库。 但是在下载文本预设存储库之前,我们需要借助 import 命令导入 NLTK,如下所示 −
mport nltk
现在,借助以下命令可以下载 NLTK 数据 −
nltk.download()
安装 NLTK 的所有可用包需要一些时间,但始终建议安装所有包。
安装其他必要的包
我们还需要一些其他 Python 包,如 gensim 和 pattern 来进行文本分析以及使用 NLTK 构建自然语言处理应用程序。
gensim − 一个强大的语义建模库,可用于许多应用程序。 可以通过以下命令安装 −
pip install gensim
pattern − 用于使 gensim 包正常工作。 可以通过以下命令安装 −
pip install pattern
Tokenization
将给定文本分解为称为标记的较小单元的过程称为标记化。 这些标记可以是单词、数字或标点符号。 也称为分词。
示例

NLTK 模块为标记化提供了不同的包。 我们可以根据我们的要求使用这些包。 这里描述了一些包 −
sent_tokenize 包 − 这个包将把输入的文本分成句子。 您可以使用以下命令导入此包 −
from nltk.tokenize import sent_tokenize
word_tokenize 包 − 这个包将把输入的文本分成单词。 您可以使用以下命令导入此包 −
from nltk.tokenize import word_tokenize
WordPunctTokenizer package − 这个包将把输入的文本和标点符号分成单词。 您可以使用以下命令导入此包 −
from nltk.tokenize import WordPuncttokenizer
词干提取
在任何语言中,单词都有不同的形式。 由于语法原因,一种语言包含许多变体。 例如,考虑单词 democracy、democratic 和 democratization。 对于机器学习和网络抓取项目,让机器理解这些不同的词具有相同的基本形式是很重要的。 因此我们可以说,在分析文本时提取词的基本形式是很有用的。
这可以通过词干提取来实现,词干提取可以定义为通过切掉词尾来提取词的基本形式的启发式过程。
NLTK 模块提供了不同的词干提取包。 我们可以根据我们的要求使用这些包。 这里描述了其中一些包 −
PorterStemmer 包 − 这个 Python 词干提取包使用 Porter 算法来提取基本形式。 您可以使用以下命令导入此包 −
from nltk.stem.porter import PorterStemmer
例如,在将词'writing'作为输入到这个词干分析器之后,输出将是词干提取后的词'write'。
LancasterStemmer 包 −这个 Python 词干提取包使用 Lancaster 的算法来提取基本形式。 您可以使用以下命令导入此包 −
from nltk.stem.lancaster import LancasterStemmer
例如,在将词 'writing' 作为该词干分析器的输入后,词干提取后的输出将是词 'writ'。
SnowballStemmer 包 − 这个 Python 词干提取包使用 Snowball 的算法来提取基本形式。 您可以使用以下命令导入此包 −
from nltk.stem.snowball import SnowballStemmer
例如,将单词"writing"作为词干分析器的输入后,词干提取后的输出将是单词"write"。
词形还原
另一种提取词的基本形式的方法是词形还原,通常旨在通过使用词汇和词法分析来去除词尾变化。 任何词经过词形还原后的基本形式称为词元。
NLTK 模块提供了以下用于词形还原的包 −
WordNetLemmatizer 包 − 它将根据单词是否用作名词或动词来提取单词的基本形式。 您可以使用以下命令导入此包 −
from nltk.stem import WordNetLemmatizer
分块
Chunking,即把数据分成小块,是自然语言处理中识别词性和名词短语等短短语的重要过程之一。 Chunking就是做token的标注。 借助分块过程,我们可以得到句子的结构。
示例
在这个例子中,我们将使用 NLTK Python 模块来实现名词短语分块。 NP分块是分块的一种,它会在句子中找到名词短语分块。
实施名词短语分块的步骤
我们需要按照下面给出的步骤来实现名词短语分块 −
步骤 1 − 分块语法定义
在第一步中,我们将定义分块的语法。 它将包含我们需要遵守的规则。
步骤 2 − 块解析器的创建
现在,我们将创建一个块解析器。 它会解析语法并给出输出。
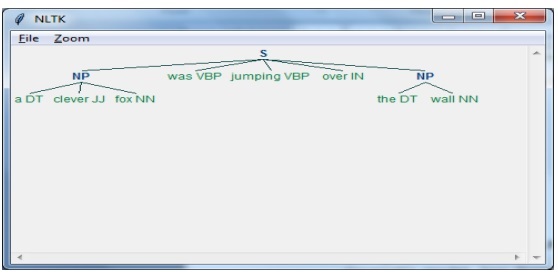
步骤 3 − 输出
在这最后一步中,输出将以树格式生成。
首先我们需要导入NLTK包如下 −
import nltk
接下来,我们需要定义句子。 这里 DT:行列式,VBP:动词,JJ:形容词,IN:介词和 NN:名词。
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]
接下来,我们以正则表达式的形式给出语法。
grammar = "NP:{<DT>?<JJ>*<NN>}"
现在,下一行代码将定义一个用于解析语法的解析器。
parser_chunking = nltk.RegexpParser(grammar)
现在,解析器将解析句子。
parser_chunking.parse(sentence)
接下来,我们在变量中给出输出。
Output = parser_chunking.parse(sentence)
在以下代码的帮助下,我们可以以树的形式绘制输出,如下所示。
output.draw()
词袋 (BoW) 模型提取文本并将其转换为数字形式
词袋 (BoW) 是自然语言处理中的一个有用模型,主要用于从文本中提取特征。 从文本中提取特征后,它可以用于机器学习算法的建模,因为原始数据不能用于 ML 应用程序。
BoW 模型的工作
最初,模型从文档中的所有单词中提取一个词汇表。 后来,使用文档术语矩阵,它会建立一个模型。 这样,BoW 模型只将文档表示为一个词袋,顺序或结构被丢弃。
示例
假设我们有下面两个句子 −
Sentence1 − 这是词袋模型的一个例子。
Sentence2 − 我们可以使用 Bag of Words 模型提取特征。
现在,通过考虑这两个句子,我们有以下 14 个不同的词 −
- This
- is
- an
- example
- bag
- of
- words
- model
- we
- can
- extract
- features
- by
- using
在 NLTK 中构建词袋模型
让我们看看下面的 Python 脚本,它将在 NLTK 中构建一个 BoW 模型。
首先导入如下包 −
from sklearn.feature_extraction.text import CountVectorizer
接下来,定义句子集 −
Sentences=['This is an example of Bag of Words model.', ' We can extract features by using Bag of Words model.'] vector_count = CountVectorizer() features_text = vector_count.fit_transform(Sentences).todense() print(vector_count.vocabulary_)
输出
表明我们在上面两个句子中有14个不同的词 −
{
'this': 10, 'is': 7, 'an': 0, 'example': 4, 'of': 9,
'bag': 1, 'words': 13, 'model': 8, 'we': 12, 'can': 3,
'extract': 5, 'features': 6, 'by': 2, 'using':11
}
主题建模:识别文本数据中的模式
通常,文档按主题分组,主题建模是一种识别文本中与特定主题相对应的模式的技术。 换句话说,主题建模用于揭示给定文档集中的抽象主题或隐藏结构。
您可以在以下场景中使用主题建模 −
文本分类
可以通过主题建模来改进分类,因为它将相似的词组合在一起,而不是将每个词单独用作特征。
推荐系统
我们可以使用相似性度量来构建推荐系统。
主题建模算法
我们可以使用以下算法来实现主题建模 −
潜在狄利克雷分配(LDA) − 它是使用概率图形模型实现主题建模的最流行的算法之一。
潜在语义分析(LDA)或潜在语义索引(LSI) − 它基于线性代数,并在文档术语矩阵上使用 SVD(奇异值分解)的概念。
非负矩阵分解 (NMF) − 它也像 LDA 一样基于线性代数。
上述算法将具有以下元素 −
- 主题数量:参数
- 文档-词矩阵:输入
- WTM(单词主题矩阵)& TDM(主题文档矩阵):输出

